Key Takeaways
- DeepSeek V4 launched in preview this week with 1.6 trillion parameters and pricing at roughly one-sixth the cost of leading US models.
- Meta unveiled Muse Spark, its first proprietary LLM, abandoning its open-source Llama strategy for frontier models.
- OpenAI released GPT-5.5, and Anthropic is testing Claude Mythos with a select group of enterprise partners.
- The Stanford AI Index 2026 confirmed AI adoption has outpaced every previous technology, with 88% of organisations now using it.
- The EU AI Act enforcement deadline is 99 days away, and US entry-level job postings have fallen 35% in 18 months.
Who is this for? Anyone who wants to stay on top of AI without wading through the noise. Whether you use AI tools for work, follow the industry out of curiosity, or want to understand what the big model releases actually mean in practice, this weekly roundup covers what mattered and why.
It was another packed week in AI. Between DeepSeek’s bombshell pricing announcement, Meta’s surprise pivot away from open source, and a new Stanford report that should concern anyone working in an entry-level role, there was no shortage of things to pay attention to.
This roundup covers the 5 stories that actually mattered between 29 April and 4 May 2026, with enough context to understand why each one is significant, not just what happened.
DeepSeek V4 Is Here and the Pricing Changes Everything

On 24 April 2026, Chinese AI lab DeepSeek quietly dropped a preview of its V4 model. And while the media coverage focused heavily on geopolitics, the number that matters most is this: V4-Pro costs $3.48 per million output tokens, while Anthropic and OpenAI charge $25 and $30 respectively for comparable frontier output.
That is not a marginal pricing difference. That is a structural shift in what frontier-grade AI costs.
DeepSeek released two variants. V4-Flash is the smaller, faster option at just $0.28 per million output tokens, undercutting GPT-5.4 Mini, Gemini 3.1 Flash, and Claude Haiku 4.5. V4-Pro is the larger model, with 1.6 trillion total parameters and 49 billion active per token using a mixture-of-experts architecture. It holds a 1-million-token context window, which means you can load the equivalent of 750,000 words into a single prompt.
Benchmark claims from DeepSeek suggest V4 performs comparably to GPT-5.4 on coding tasks and closes much of the gap with frontier models on reasoning. It still trails OpenAI’s GPT-5.4 and Google’s Gemini 3.1 Pro on broad knowledge benchmarks, but the lab itself wrote that this gap represents “a developmental trajectory approximately 3 to 6 months behind state-of-the-art models.” At one-sixth the price, that gap becomes a very reasonable trade-off for many use cases.
There are two dimensions worth watching beyond the benchmarks.
The first is chip independence. DeepSeek trained and serves V4 on Huawei’s Ascend AI processors, not Nvidia hardware. Counterpoint Research principal analyst Wei Sun said this “allows AI systems to be built and deployed without relying solely on Nvidia,” which could have significant implications for global AI development and Chinese AI sovereignty under US export restrictions.
The second is the legal cloud hanging over the release. The White House accused foreign entities of conducting “industrial-scale” campaigns to copy frontier US models, and Anthropic and OpenAI have both separately accused DeepSeek of distillation attacks, essentially extracting capabilities from their proprietary models. China’s foreign ministry called these claims “groundless.” DeepSeek itself has not commented publicly.
As a preview, V4 is still being refined. DeepSeek has not committed to a timeline for the final production release. But both V4-Flash and V4-Pro are live on the official API now, and both models support the same 1-million-token context. Legacy model aliases (deepseek-chat and deepseek-reasoner) are set to be retired on 24 July 2026.
What it means for you: If you’re building anything with AI and cost is a constraint, V4 is now worth evaluating seriously. If you’re simply watching the industry, this release confirms that the gap between US and Chinese frontier AI is closing faster than most expected.
External reference: DeepSeek V4 official API documentation
Meta Abandons Open Source at the Frontier with Muse Spark

For three years, Meta’s AI identity was built on open source. Llama gave developers free access to capable models and helped Meta position itself as the democratising force in AI. That era appears to be ending, at least at the frontier.
This week, Meta unveiled Muse Spark, its first proprietary large language model, built under Chief AI Officer Alexandr Wang’s newly formed Superintelligence Labs. Unlike Llama, Muse Spark is closed. You cannot download it, fine-tune it locally, or build on its weights. Meta now controls access entirely.
According to reporting, Muse Spark delivers competitive performance on multimodal perception, reasoning, health, and agentic tasks. Simultaneously, Meta announced it plans to spend $115 to $135 billion on AI capital expenditures in 2026, nearly double last year’s figure. That is an enormous bet on catching up with OpenAI and Google at the frontier.
The strategic signal is significant. Meta building a proprietary frontier model means the competitive pressure at the top of the AI field reached a threshold where releasing weights is no longer viable as a strategy. If you built your stack assuming Meta’s best models would always be free, that assumption now needs revisiting.
Meta’s open-source models (the Llama family) are not going away. But the best models Meta builds going forward may not be.
OpenAI Ships GPT-5.5 and Updates Its Image Generator
OpenAI released GPT-5.5 this week alongside an updated version of its image generation model. GPT-5.5 is the latest iteration of its flagship offering.
Notably, OpenAI is advising developers not to carry over prompts from older GPT versions when moving to 5.5. Instead, the recommendation is to start from scratch with minimal prompts and build from there. Role definitions, which many practitioners had moved away from, are reportedly back as an effective technique with the newer model.
GPT-5.4 Thinking, an earlier release this cycle, had already crossed a notable milestone: it scored 75% on OSWorld-Verified, a desktop task benchmark designed to measure an AI’s ability to control a computer autonomously. That was a 27.7 percentage-point improvement over GPT-5.2 and represents a meaningful step toward genuinely autonomous AI agents that can navigate files, browsers, and applications on your behalf.
For most users, GPT-5.5 is simply the most capable version of ChatGPT yet. For developers, the prompt-reset recommendation is worth taking seriously before migrating.
Anthropic’s Claude Mythos: The Most Capable Model Nobody Can Use Yet
Anthropic is testing its Claude Mythos model with a select group of organisations. The company describes it as the most capable model it has ever built, and restricted access to 50 companies under a programme called Project Glasswing.
Mythos scored 93.9% on SWE-bench Verified (a software engineering benchmark) and 94.6% on GPQA Diamond, a benchmark made up of graduate-level questions in biology, physics, and chemistry where PhD experts average 65%. Those are extraordinary numbers.
The reason for restricted access is not commercial strategy. Anthropic says the model independently identified thousands of zero-day vulnerabilities across major operating systems and browsers during testing. The company judged that level of capability too risky for a general public release at this stage.
This is one of the most interesting inflection points in AI safety so far. A model too capable to release is not a theoretical concern. It is a real product decision Anthropic has already made.
For the rest of us, Claude Sonnet 4.6 and Opus 4.6 remain the publicly available Claude models, both of which continue to rank among the top-performing AI tools you can actually use today.
Google’s Latest TPUs Are Built for the Agentic Era
At Google Cloud Next this week, Google announced its eighth-generation Tensor Processor Units (TPUs), coming in two distinct architectures: TPU 8t (optimised for training) and TPU 8i (optimised for inference).
The design philosophy behind these chips is worth noting. Rather than a general-purpose chip that tries to do everything, Google has separated training and inference into purpose-built silicon. This reflects a broader industry shift, as agentic AI workflows, where models execute multi-step tasks autonomously, place very different computational demands on infrastructure compared to simple query-response interactions.
Google also released Gemma 4, its open-weight model under Apache 2.0 licensing, with variants up to 31 billion parameters. The 31B version currently ranks third globally among all open models on the Arena AI leaderboard, with no commercial restrictions.
The Stanford AI Index 2026: Key Takeaways
The Stanford AI Index for 2026 dropped this week, and it is the most comprehensive snapshot of where AI actually stands. A few numbers are worth highlighting.
The top AI models can now answer more than 50% of questions on a benchmark so difficult that PhD experts average 65%. Just 12 months ago, the best models scored 8.8%. That rate of improvement on hard reasoning tasks is genuinely remarkable.
AI adoption has outpaced every previous consumer technology. More than 88% of organisations now use AI in some form. More than half of all people worldwide have used AI, and university students are at roughly 80% adoption. For comparison, the internet and personal computer each took significantly longer to reach similar penetration.
The US still leads in frontier model releases, but China is closing the gap quickly. According to the report, as of March 2026, Anthropic leads the Arena AI leaderboard, followed closely by xAI, Google, and OpenAI. Chinese models lag only modestly.
One tension the report flags: AI companies are sharing less about how their models are trained, and independent benchmark results sometimes contradict what labs report themselves. The absence of a model from certain safety benchmarks, the report notes, may itself be informative.
External reference: Stanford AI Index 2026, MIT Technology Review coverage
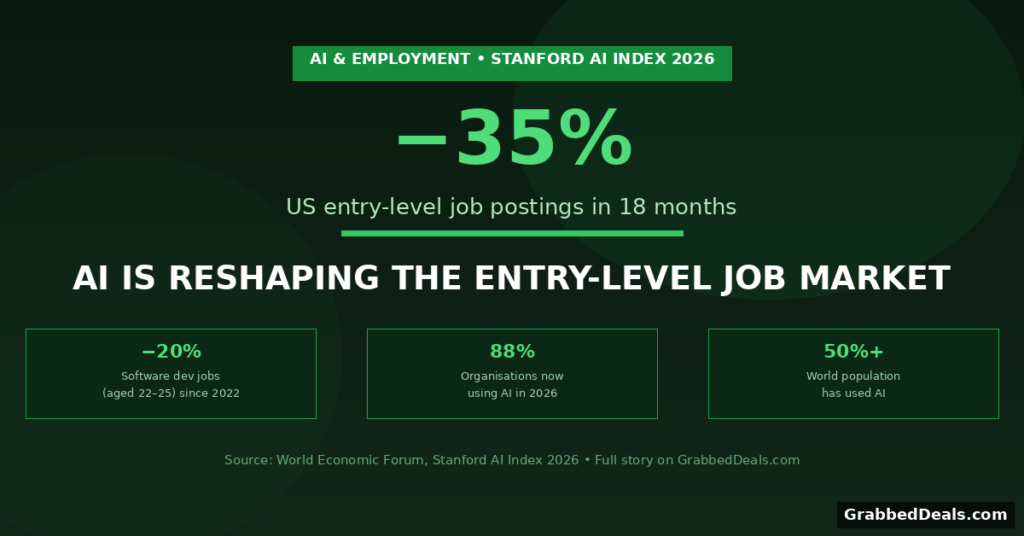
AI and Jobs: Entry-Level Hiring Falls 35% in 18 Months
This is the story from this week that will matter most to the most people.
Speaking to BBC Newsnight on 22 April, former UK Prime Minister Rishi Sunak said that graduates’ concerns about AI “flattening” entry-level hiring are “justified.” He cited World Economic Forum data showing US entry-level job postings have fallen 35% in the past 18 months, with parallel declines in the UK.
Sunak referenced private conversations with CEOs across law, accountancy, and creative industries who confirmed AI is handling the work that would previously have gone to junior hires. This is not a future concern. It is a present one.
A separate study from economists at Stanford, referenced in the AI Index, found employment for software developers aged 22 to 25 has fallen nearly 20% since 2022. That aligns with the broader pattern: tasks that used to require a junior human are increasingly handled by AI, starting at the bottom of career ladders.
None of this means AI eliminates work entirely. It means the shape of entry-level work is changing faster than most hiring pipelines have adjusted to, and the people entering the workforce right now are navigating something genuinely new.
Novo Nordisk Partners with OpenAI for Full Business Integration
Danish pharmaceutical company Novo Nordisk announced a strategic partnership with OpenAI this week, with plans to integrate AI across its entire business by the end of 2026. That covers drug discovery, clinical trials, manufacturing, supply chains, and commercial operations.
CEO Mike Doustdar framed the goal as using AI to “supercharge” scientists rather than replace them. But Novo also acknowledged that AI would reduce future hiring growth.
This is one of the most comprehensive enterprise AI integrations announced so far by a major pharmaceutical company. It is worth watching as a case study in what full-stack AI deployment looks like in a highly regulated industry.
EU AI Act Countdown: 99 Days to Go
If you run a business that uses AI in recruitment, performance management, or customer-facing decisions, the EU AI Act’s main enforcement window opens on 2 August 2026, now under 100 days away.
Most AI used in hiring and performance evaluation is classified as “high-risk” under the Act’s Annex III. That classification triggers requirements for a quality management system, technical documentation, and conformity records before the deadline.
Gartner predicts that by 2028, explainable AI will drive 50% of LLM observability investments, as companies try to build auditable, reversible agentic workflows. If you have not already audited the AI tools you use in regulated contexts, this is the week to start.
What to Watch Next Week
Several things are worth tracking as Week 3 begins.
DeepSeek V4 is still in preview. Expect further benchmark results and developer feedback to shape its final release timeline. The pricing implications for anyone building on frontier models will only become clearer as real-world performance data accumulates.
OpenAI’s Cerebras chip deal, worth more than $20 billion over three years, is a significant infrastructure bet that could reshape how OpenAI scales inference. Watch for capacity and latency improvements as that partnership develops.
The EU AI Act deadline on 2 August is 99 days away. Regulatory stories will accelerate from here, particularly for companies operating in HR, legal, and financial services.
FAQs
What is DeepSeek V4 and why does it matter? DeepSeek V4 is the latest large language model from Chinese AI lab DeepSeek, released in preview on 24 April 2026. It comes in two variants, V4-Flash and V4-Pro, both with a 1-million-token context window. The most significant aspect is the pricing. V4-Pro costs $3.48 per million output tokens, compared to $25 from Anthropic and $30 from OpenAI for comparable frontier models. For developers and businesses using AI at scale, this makes V4 worth serious evaluation.
What is Meta Muse Spark? Muse Spark is Meta’s first proprietary large language model, launched under the company’s new Superintelligence Labs. Unlike Meta’s Llama models, Muse Spark is closed source. This marks a significant strategic shift for Meta, which built its AI reputation on open-source releases. Muse Spark competes at the frontier level and is not publicly available in the same way Llama models are.
Is GPT-5.5 worth upgrading to from GPT-5.4? OpenAI released GPT-5.5 this week but specifically advised developers to start fresh with prompts rather than carry over existing ones. If you are a developer building on the API, that is a meaningful signal that the model’s behaviour has changed enough to warrant a prompt review. For general ChatGPT users, GPT-5.5 is simply a more capable version of what you already use.
What is Claude Mythos and can I use it? Claude Mythos is Anthropic’s most capable model to date, but it is not available to the public. Access is restricted to 50 organisations under Project Glasswing. Anthropic made this decision because the model demonstrated the ability to identify thousands of zero-day security vulnerabilities independently, which the company judged too risky to release broadly. Most users should continue with Claude Sonnet 4.6 or Opus 4.6.
What does the EU AI Act mean for my business? If your business operates in the EU or processes data from EU residents using AI, the main enforcement window opens on 2 August 2026. AI used in hiring, performance reviews, or customer decisions is typically classified as high-risk, which means you need documented quality management, technical records, and conformity assessments. If you have not yet started this process, begin now.
Conclusion
This was one of the most consequential weeks in AI for 2026 so far. DeepSeek’s pricing move reshapes the cost structure of frontier AI. Meta’s proprietary pivot signals a new competitive reality. And the Stanford Index and jobs data together paint a picture of an industry moving faster than the systems around it, employment markets, regulatory frameworks, and individual careers included, can comfortably absorb.
The week’s clearest takeaway: the AI race is no longer primarily about which model is technically best. It is about cost, safety, autonomy, and governance. All four dimensions moved significantly this week.
Come back next Sunday for the full roundup covering 5 to 11 May 2026. Same page, fresh content.
Related Posts
- ChatGPT vs Claude vs Gemini: Which AI Chatbot Wins in 2026?
- Best AI Tools for Productivity in 2026: Our Top Picks
- Perplexity AI Review 2026: Is It the Best AI Search Engine?
Explore our more pages – AI Tools & Productivity | Smartphone Ecosystems | Laptop & PCs | Audio & Sound Systems | Gaming | Photography & Videography | EV & Green Tech | Digital Marketing & SEO | Smart Home & Wearables | Tech Deals & Buying Guides |
Author bio: The GrabbedDeals editorial team tests AI tools, tech products, and software so you don’t have to. Every review and comparison on this site is written after hands-on testing with real tasks.