DeepSeek V4 is the most talked-about AI release of 2026, and for good reason. Dropped on 24 April 2026, it delivers near-frontier coding performance under a fully open licence at a price that undercuts GPT-5.5 by roughly 7 times. If you keep seeing the name and can’t quite place why it matters, this explainer covers everything you need to know in plain English.
Key takeaways
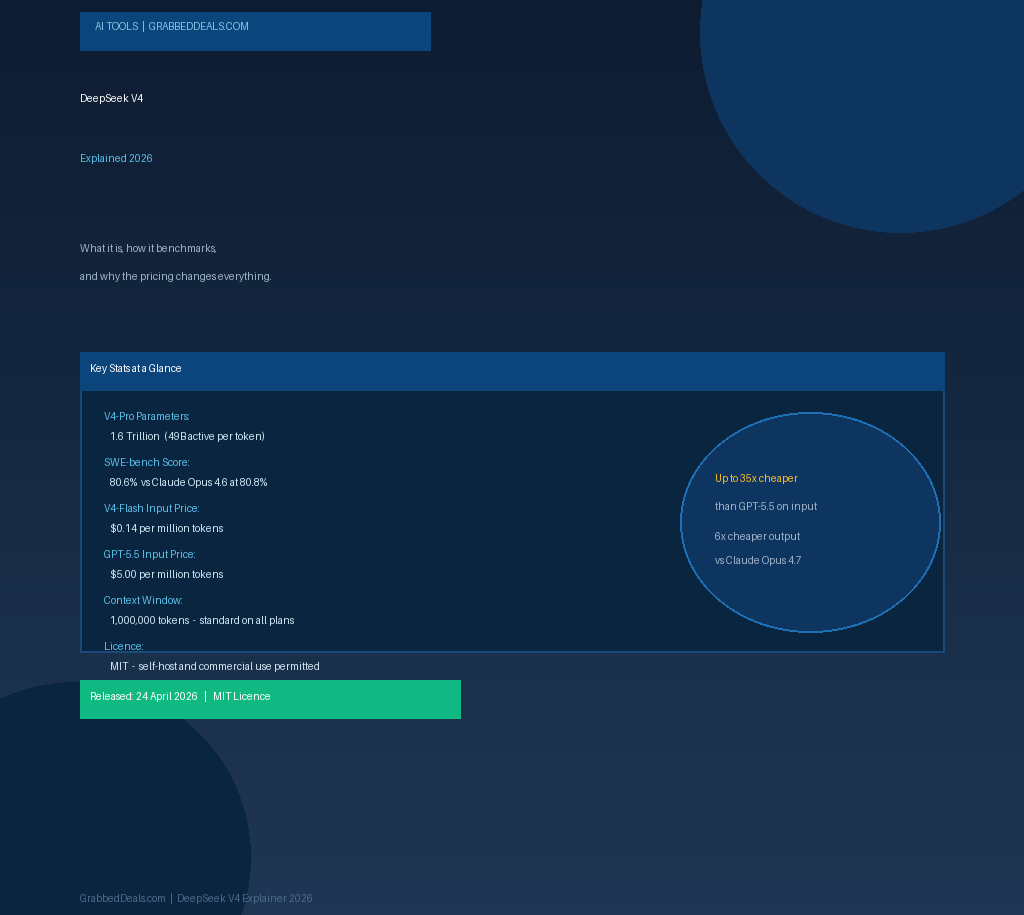
- DeepSeek V4 launched 24 April 2026 as two models: V4-Pro (1.6 trillion parameters) and V4-Flash (284 billion parameters), both under the MIT licence.
- V4-Pro scores 80.6% on SWE-bench Verified, just 0.2 points behind Claude Opus 4.6, at a fraction of the price.
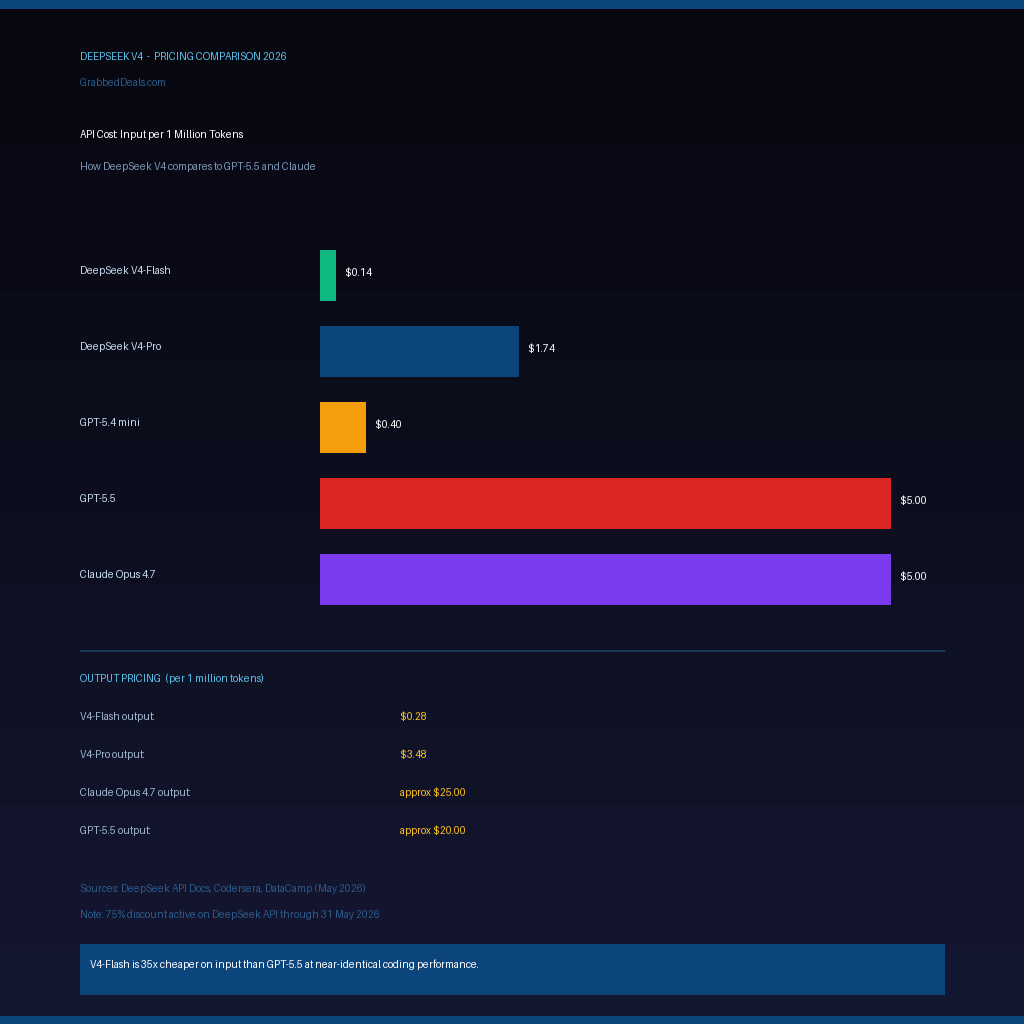
- V4-Flash input pricing starts at $0.14 per million tokens. GPT-5.5 input costs $5 per million. That is a 35x gap.
- Both models support a 1-million-token context window as standard, made practical by a new hybrid attention architecture.
- The open weights are available on Hugging Face. Developers can self-host or access the models via the DeepSeek API.
What DeepSeek V4 actually is
DeepSeek is a Chinese AI research lab that made headlines in January 2025 when its R1 model matched OpenAI’s o1 at a fraction of the cost. V4 is its biggest release since then.
The V4 family consists of two models released simultaneously. DeepSeek-V4-Pro is the flagship: 1.6 trillion total parameters, with 49 billion active per token. DeepSeek-V4-Flash is the speed-optimised option: 284 billion total parameters, 13 billion active per token. Both use a Mixture-of-Experts (MoE) architecture, which means only a portion of the total parameters are used for any given request, keeping inference costs lower than a comparable dense model would require.
Both models are available through the DeepSeek API, through the chat.deepseek.com interface (listed as Expert Mode and Instant Mode respectively), and as open weights on Hugging Face. The licence is MIT, meaning commercial use, fine-tuning, and self-hosting are all permitted without restrictions.
Why the pricing is the real story
The benchmark numbers are impressive, but the pricing is what made the tech world pay attention.
V4-Flash input costs $0.14 per million tokens. V4-Pro input costs $1.74 per million tokens. Compare that to GPT-5.5 at approximately $5 per million tokens on input, and Claude Opus 4.7 at a similar tier. For output tokens, V4-Pro is priced at $3.48 per million, roughly 6 times cheaper than comparable proprietary alternatives.
For a team running high-volume API workloads, this pricing gap is significant. A workflow that costs $500 per month on GPT-5.5 could run on V4-Pro for around $70 to $80. V4-Flash would bring that down further still.
An independent pricing analysis by DeepInfra found that across seven benchmarks, V4-Pro was more cost-efficient than GPT-5.4 mini on five out of seven tasks, even after accounting for V4’s higher verbosity. The cost advantage is real, not just a headline number.
How the benchmarks stack up
The numbers matter because they tell you whether the price difference comes at a meaningful quality cost.
On SWE-bench Verified, the standard test for real-world software engineering tasks, V4-Pro scores 80.6%. Claude Opus 4.6 scores 80.8%. That is a 0.2-point gap at roughly a seventh of the price. On LiveCodeBench, V4-Pro posts 93.5, the highest score of any model at the time of release. On Codeforces, its rating of 3,206 beats GPT-5.4’s 3,168.
The gaps appear in other areas. On Humanity’s Last Exam (HLE), which tests expert-level cross-domain reasoning, V4-Pro scores 37.7% against Claude’s 40.0% and Gemini 3.1 Pro’s 44.4%. On factual knowledge retrieval (SimpleQA-Verified), Gemini holds a meaningful lead at 75.6% against V4-Pro’s 57.9%.
A NIST evaluation by the Center for AI Standards and Innovation (CAISI) in April 2026 placed V4-Pro’s overall capability roughly 8 months behind the current US frontier, noting that it performs similarly to GPT-5 rather than the most recent frontier models. DeepSeek’s own self-reported evaluations present a more favourable picture, which is worth factoring into your expectations.
The honest summary: for coding and software engineering tasks, V4-Pro is genuinely competitive with the best proprietary models. For complex reasoning and knowledge-heavy tasks, a gap remains.
The architecture behind the 1-million-token context
One feature that sets V4 apart from most models is that a 1-million-token context window is standard across all DeepSeek services, not a premium tier. This matters for long document analysis, large codebases, and extended research workflows.
What makes this practical is a new hybrid attention architecture combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). According to DeepSeek’s technical documentation, this design means V4-Pro uses only 27% of the inference FLOPs and 10% of the KV cache that V3.2 required at 1 million tokens. In practical terms, long-context requests that would have been cost-prohibitive on earlier models are now economically viable.
The model also introduces a Muon optimiser in place of AdamW for most parameters, which DeepSeek reports produces faster convergence and more stable training at trillion-parameter scale.
Who should actually use DeepSeek V4
V4-Pro is the better choice for teams doing code generation, software engineering assistance, or agentic coding workflows where per-token costs add up quickly. The SWE-bench parity with Claude at a fraction of the cost is a meaningful advantage for those specific use cases.
V4-Flash is worth considering for high-throughput applications where near-Pro coding performance is acceptable and speed or cost is the primary constraint. The 1.6-point gap between Flash and Pro on SWE-bench is small enough that most teams would not notice it in practice.
For tasks requiring strong factual recall, complex multi-domain reasoning, or the highest available general intelligence scores, the current proprietary frontier models still hold an edge. DeepSeek’s own documentation acknowledges that V4 is a preview release, with further refinements planned. Teams building on it in production should account for potential model updates.
V4 is also available through third-party providers including Fireworks, Together.ai, and OpenRouter, which gives teams flexibility on latency and deployment preferences beyond the direct DeepSeek API.
Final verdict
DeepSeek V4 is a significant release for anyone working with AI at scale, particularly developers and engineering teams. The pricing compression it represents is real: near-frontier coding performance at a fraction of what proprietary alternatives charge. It is not the best model at everything, and the CAISI evaluation suggests the gap to the absolute frontier is wider than DeepSeek’s own benchmarks imply. But for coding tasks specifically, it competes with the best in class. For businesses where API costs are a limiting factor, it is worth serious evaluation.
Frequently asked questions
What is DeepSeek V4 and when was it released?
DeepSeek V4 is a family of two open-weight large language models, V4-Pro and V4-Flash, released by Chinese AI lab DeepSeek on 24 April 2026. Both models use a Mixture-of-Experts architecture and are licensed under the MIT licence, meaning they can be used commercially, fine-tuned, and self-hosted without restrictions.
How does DeepSeek V4 compare to GPT-5.5 and Claude?
On coding benchmarks, V4-Pro scores 80.6% on SWE-bench Verified, just 0.2 points behind Claude Opus 4.6. Its Codeforces rating of 3,206 exceeds GPT-5.4’s score. The gap widens on complex reasoning and factual recall tasks, where GPT-5.5 and Gemini 3.1 Pro hold clearer leads.
Is DeepSeek V4 free to use?
The model weights are available for free on Hugging Face under an MIT licence. API access is paid, with V4-Flash priced at $0.14 per million input tokens and V4-Pro at $1.74 per million input tokens. There is a 75% discount on listed API prices through 31 May 2026.
Can DeepSeek V4 handle a 1-million-token context window?
Yes. A 1-million-token context window is standard across both V4-Pro and V4-Flash. This is made practical by a hybrid attention architecture that reduces inference compute to 27% and KV cache to 10% of the previous V3.2 model at that context length.
Is DeepSeek V4 safe to use for commercial projects?
The MIT licence permits commercial use. However, as V4 is a preview release, DeepSeek has indicated that the model may change with future updates. Teams running it in production should plan for potential breaking changes and test domain-specific performance before committing to a migration.
Author: The GrabbedDeals editorial team tests and reviews tech across every major category, from smartphones and laptops to AI tools and smart home devices. Our buying guides are built on the latest real-world data, independent expert reviews, and current pricing.
Explore our more pages – AI Tools & Productivity | Education & Learning | Travel | Smartphone Ecosystems | Laptop & PCs | Audio & Sound Systems | Gaming & Photography | EV & Green Tech | Digital Marketing & SEO | Smart Tech Deal & Buying Guides