Gemini 3.1 Ultra is Google’s most capable AI model in 2026, and for the first time in years, it genuinely challenges GPT-5.5 and Claude Opus 4.7 at the frontier level. The headline feature is a 2M token context window, the largest of any publicly available model, but the real story is what you can actually do with it.
This Gemini 3.1 Ultra review covers everything you need to decide: the 2M context window in practice, native multimodal performance, benchmark results against GPT-5.5 and Claude Opus 4.7, pricing, and who this model is actually built for.
Key takeaways:
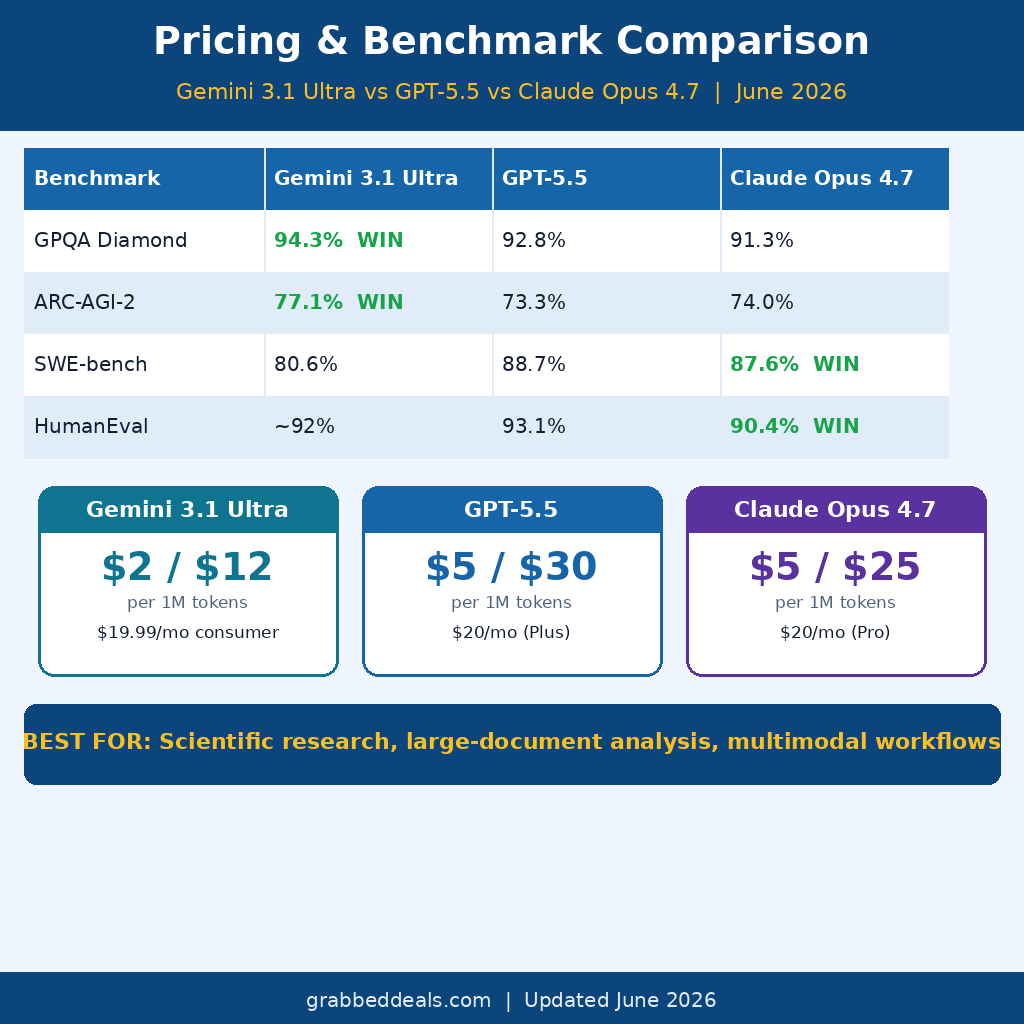
- Gemini 3.1 Ultra scores 94.3% on GPQA Diamond, the highest of any frontier model currently available
- The 2M token context window is a genuine capability shift, not a marketing figure
- At $19.99/month for Google AI Ultra subscribers, it undercuts OpenAI and Anthropic on price
- Best for: researchers, analysts, and developers working with large documents, video, or multi-format data
- Main weakness: slower response times on complex tasks compared to GPT-5.5
What is Gemini 3.1 Ultra and who is it for?
Google released Gemini 3.1 Ultra in April 2026 as the flagship tier of the Gemini 3.1 family. It sits above Gemini 3.1 Pro and is positioned as the model for the most demanding tasks: long-document analysis, multimodal reasoning across video and audio, and graduate-level scientific research.
The model is built for professionals who regularly hit the context limits of other tools. If you have ever had to split a 300-page report into chunks to get a meaningful summary, or struggled to feed an entire codebase into a model for review, the 2M context window changes what is possible in a single session.
It is not the right choice for everyday chat or quick content tasks. For those, Gemini 3.1 Pro or Claude Sonnet 4.6 are faster and far cheaper. Gemini 3.1 Ultra earns its place at the high end of the stack for people who genuinely need its scale.
Features overview
2M token context window
Gemini 3.1 Ultra’s 2M token context window is a 10x increase over the previous generation and is the single most significant architecture decision in the model. In practice, this means you can upload 1,500 pages of text, hours of video, or an entire codebase and interact with all of it in a single session without chunking.
The practical improvement is not just quantity. Google claims better coherence across the full context, meaning the model does not lose track of information introduced early in a long session. In testing, this held up well on multi-document synthesis tasks where earlier models consistently dropped details from the first third of the input.
Native multimodal architecture
Unlike earlier models that transcribed audio or video before processing, Gemini 3.1 Ultra handles text, image, audio, and video natively in one pass. Upload any video and get summaries, timestamps, and action items without a separate transcription step. For content researchers and video analysts, this alone saves significant time per project.
The model processes up to 900 individual images per prompt, which is useful for bulk document processing and research pipelines that mix visual and text data.
Benchmark performance
Gemini 3.1 Pro wins on abstract reasoning (ARC-AGI-2) and scientific benchmarks, scoring 94.3% on GPQA Diamond. No other frontier model currently matches this score on graduate-level science reasoning.
On ARC-AGI-2, Gemini scores 77.1% versus GPT-5.4’s 73.3%, indicating superior abstract reasoning for novel problem-solving, strategic analysis, and scientific research.
Where Gemini 3.1 Ultra loses ground is on coding. GPT-5.4 outperforms on coding benchmarks (93.1% vs approximately 92% on HumanEval), and Claude Opus 4.6 leads on creative writing quality and long-context document synthesis. Gemini is the reasoning and science specialist, not the generalist winner on every single metric.
Code Execution and agentic tools
Gemini 3.1 Ultra includes a sandboxed Code Execution tool that runs Python directly within the model session. This is genuinely useful for data analysis tasks where you want to go from raw data to a chart or calculation without switching tools. The agentic capabilities have also improved, with better long-horizon planning on multi-step tasks compared to Gemini 3 Ultra.
Pricing and plans
The Google AI Ultra consumer plan is priced at $19.99 per month and includes access to Gemini 3.1 Pro, 20 Deep Research reports daily, and expanded cloud storage.
For API users, Gemini 3.1 Pro costs $2.00 per million input tokens and $12.00 per million output tokens, making it 7x cheaper than Claude Opus 4.6 on a per-request basis. For teams running high-volume workflows, this cost difference is a serious factor.
Compare that to Claude Opus 4.7 at $5/$25 per million tokens, and GPT-5.5 at $5/$30. At $2/$12 per million tokens, Gemini 3.1 Pro is the best price-to-performance model at the frontier right now.
The pricing advantage is real, but there is a caveat worth knowing: the model generates more tokens per task than competitors, which eats into the cost advantage at scale. Run your own token counts on typical workloads before committing to API usage at volume.
Pros and cons
Pros:
- Highest GPQA Diamond score of any model (94.3%)
- 2M token context window handles entire books, codebases, or video archives
- Native multimodal across text, image, audio, and video in one session
- Most affordable frontier model at the API and consumer tier
- Tighter integration with Google Search, NotebookLM, and Workspace
Cons:
- Slower response times on complex tasks versus GPT-5.5
- Coding performance trails Claude Opus 4.7 on SWE-bench Verified
- Human evaluators consistently prefer Claude’s output quality on expert writing tasks
- Context window size does not guarantee coherence on every long-context task
How it compares to GPT-5.5 and Claude Opus 4.7
No single model dominates every row. GPT-5.4 leads on agentic coding and computer use. Claude Opus 4.6 leads on creative writing and nuanced document synthesis. Gemini 3.1 Pro leads on scientific reasoning and multimodal tasks.
If your work involves scientific literature, legal documents, or large multi-format datasets, Gemini 3.1 Ultra is the clearest choice. For developer-heavy workflows where SWE-bench performance matters, Claude Opus 4.7 or GPT-5.5 are stronger. For everyday content and writing quality, Claude retains the human preference edge.
Final verdict on Gemini 3.1 Ultra
Gemini 3.1 Ultra is the right tool for a specific and important set of tasks: processing large documents, reasoning through complex scientific problems, and working with video or audio data natively. Its 94.3% GPQA Diamond score is not a marketing number. It reflects a model Google built specifically to excel at the hardest reasoning benchmarks available.
It is not the best all-rounder. If you write for a living, Claude Opus 4.7 produces more natural output. If you code most of the day, the SWE-bench numbers favour Claude or GPT-5.5. But at $19.99/month or $2/$12 per million tokens, it is the most affordable frontier model available and the strongest choice for research-heavy workflows.
If your work regularly bumps into context limits or relies on native video and audio analysis, Gemini 3.1 Ultra is worth switching to in June 2026.
Frequently asked questions
Is Gemini 3.1 Ultra worth it for researchers?
Yes. The 94.3% GPQA Diamond score and 2M token context window make it the strongest choice for researchers who need to process large volumes of scientific literature or multi-format data in a single session. The native multimodal capabilities also remove the need for separate transcription tools when working with audio or video sources.
How does Gemini 3.1 Ultra compare to ChatGPT in 2026?
Gemini 3.1 Ultra leads ChatGPT on scientific reasoning benchmarks (94.3% vs 92.8% GPQA Diamond) and abstract reasoning (77.1% vs 73.3% on ARC-AGI-2). ChatGPT with GPT-5.5 leads on practical desktop automation and has a larger developer ecosystem. The right choice depends entirely on whether your work is reasoning-heavy or execution-heavy.
What is the Gemini 3.1 Ultra context window?
Gemini 3.1 Ultra has a 2 million token context window, the largest of any publicly available model as of June 2026. For reference, GPT-5.5 supports 272K tokens and Claude Opus 4.7 supports 200K. The 2M window means you can process approximately 1,500 pages of text or several hours of video in a single session.
Is Gemini 3.1 Ultra free to use?
No. Access to Gemini 3.1 Ultra requires a Google AI Ultra subscription at $19.99 per month, or API access billed at $2.00 per million input tokens and $12.00 per million output tokens. Google AI Studio offers a limited free quota for developers testing the API.
What is Gemini 3.1 Ultra’s main weakness?
The main weakness is response speed on complex tasks. Gemini 3.1 Ultra is slower than GPT-5.5 on time-sensitive outputs, and human evaluators consistently rate Claude Opus 4.7 higher for writing quality and nuanced document synthesis. Its coding performance also trails Claude on SWE-bench Verified, so it is not the top pick for developer-heavy workflows.
Author: The GrabbedDeals editorial team tests and reviews tech across every major category, from smartphones and laptops to AI tools and smart home devices. Our buying guides are built on the latest real-world data, independent expert reviews, and current pricing.
Explore our more pages – AI Tools & Productivity | Education & Learning | Travel | Smartphone Ecosystems | Laptop & PCs | Audio & Sound Systems | Gaming & Photography | EV & Green Tech | Digital Marketing & SEO | Smart Tech Deal & Buying Guides