The first week of June 2026 in AI was not quiet. Google I/O opened on 19 May with a new Gemini model expected, Claude Opus 4.7 is now the default Anthropic frontier model after its April launch, GPT-5.5 has been live on the API since 24 April, and DeepSeek V4 Flash continues to reshape how developers think about model pricing. Here is everything that mattered from 26 May to 1 June 2026, with no filler.
Key Takeaways
- Google I/O 2026 (19-20 May) unveiled a new Gemini update expected to land at roughly GPT-5.5 level, below Claude Mythos Preview on benchmarks
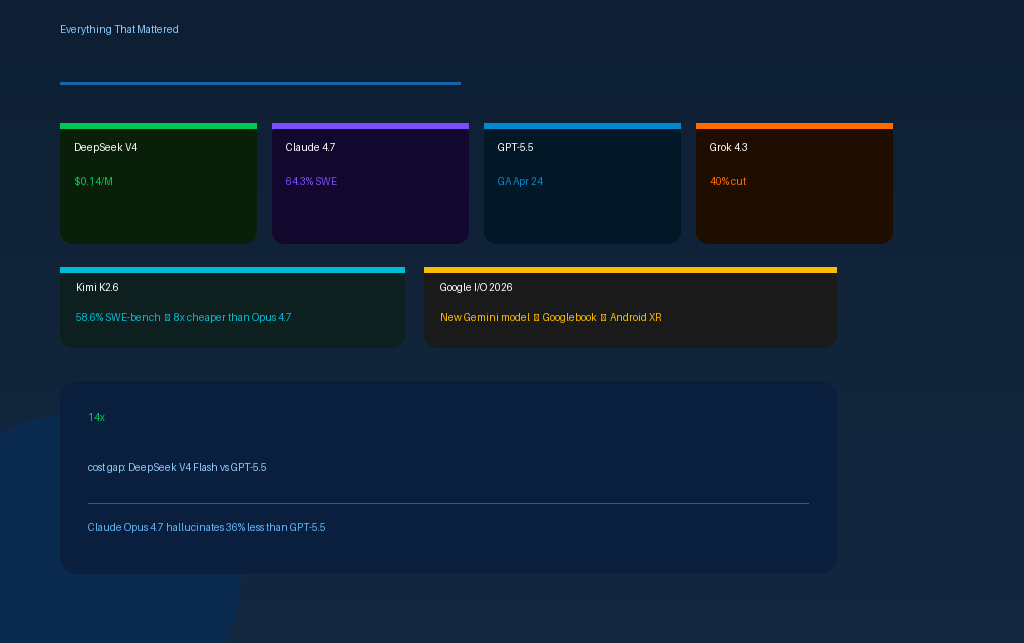
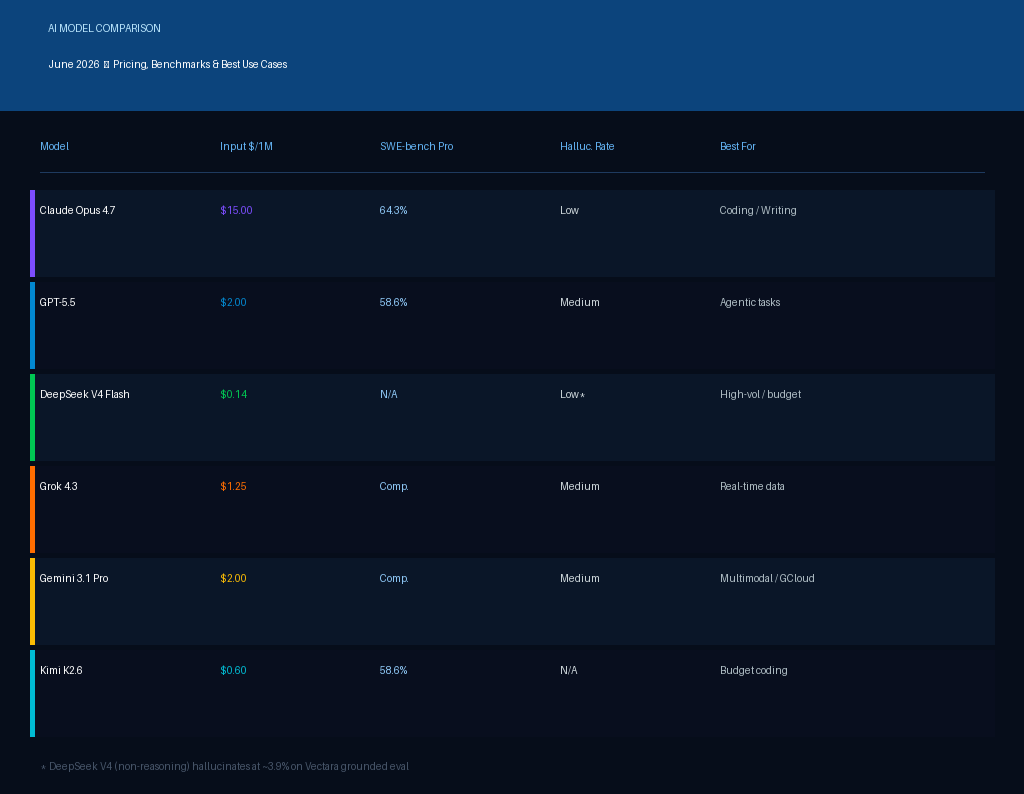
- Claude Opus 4.7 is Anthropic’s generally available frontier model, leading SWE-bench Pro at 64.3% and hallucinating 36% less than GPT-5.5
- DeepSeek V4 Flash at $0.14 per million input tokens is still the most disruptive cost story in the AI market, running on Huawei Ascend hardware
- Grok 4.3 went GA on 30 April with a 40% input price cut and a 1-million token context window, yet remains underreported
- Kimi K2.6 from Moonshot AI emerged as a serious open-weight coding challenger, matching GPT-5.5 on SWE-bench Pro at 8x lower cost than Opus 4.7
Google I/O 2026 and what the new Gemini actually means
Google I/O opened on 19 May at Shoreline Amphitheatre, and the central question going in was not whether Google would announce AI features but whether its AI could still compete. The short answer is: competently, not dominantly.
The expected Gemini update, likely Gemini 3.2 or 3.5 based on Google’s typical three-to-four month release cadence, is described by multiple sources as a meaningful improvement in reasoning and multimodal tasks. It is not a step-change. Coding performance, the benchmark that has turned Anthropic’s Claude into the default choice for most developers, remains an area where Google is working to close the gap rather than lead it. Google’s own internal coding platform, Antigravity, is heavily used inside the company but has not yet achieved the external traction of Claude Code or OpenAI’s Codex.
The confirmed product slate at I/O was substantial: Googlebook (a Gemini-first laptop category), Aluminium OS, Android XR glasses, Gemini Intelligence, and Android 17. Alphabet also announced Gemma 4 inference optimization and revealed that its Isomorphic Labs spinoff raised a $2.1 billion Series B for AI drug design.
For everyday users, the Gemini update matters. For developers benchmarking against Anthropic and OpenAI, it is a catch-up release, not a capability leap.
Claude Opus 4.7: what changed and why it matters
Anthropic launched Claude Opus 4.7 on 16 April and it is now the standard frontier model across all Claude products, the API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
The headline improvement is software engineering. Opus 4.7 scores 64.3% on SWE-bench Pro, a 10.9-point jump from Opus 4.6’s 53.4%. To put that in practical terms, it autonomously resolves roughly 200 more software engineering tasks per 1,865-task benchmark run than its predecessor. Early testing from CodeRabbit found that recall improved by over 10% on complex pull requests. Developers using Warp describe it as measurably more thorough on difficult tasks.
Beyond code, Opus 4.7 has better vision, processing images at higher resolution, and produces noticeably higher-quality outputs for professional tasks including interfaces, slides, and documents. Anthropic also introduced new cybersecurity safeguards on this model, with automatic detection and blocking of prohibited uses. Security professionals can join Anthropic’s Cyber Verification Program for legitimate penetration testing and vulnerability research access.
Hallucination reliability is a key differentiator: Claude Opus 4.7 hallucinates at a 36% lower rate than GPT-5.5 on Artificial Analysis’s evaluation, according to benchmark data from Build Fast with AI. For tasks where factual precision matters, that gap is worth knowing.
GPT-5.5, DeepSeek V4, and Grok 4.3: the competitive field right now
The current AI frontier is a four-horse race with no single winner across all categories, and that is a meaningful shift from how the market looked a year ago.
GPT-5.5 launched on 24 April and is now available via API. OpenAI’s focus was agentic capability: the model excels at multi-step workflows across coding, data analysis, document creation, and computer use. It scored 82.7% on Terminal-Bench 2.0 and 78.7% on OSWorld-Verified, leading both benchmarks. Senior engineers in early testing described it as stronger than Opus 4.7 at reasoning autonomy. However, its hallucination rate in reasoning mode exceeds 10%, compared to Claude’s lower factual error rate on comparable tasks.
DeepSeek V4 continues to drive the biggest pricing conversation in the market. V4 Flash, released 24 April, sits at $0.14 per million input tokens compared to GPT-5.5’s estimated $2.00. That is a 14x gap at comparable benchmark performance on many routine tasks. V4 Pro, with 1.6 trillion total parameters and 49 billion active per forward pass, runs entirely on Huawei Ascend chips with no NVIDIA hardware involved. The combination of open Apache 2.0 licensing and this pricing makes it the default starting point for high-volume production workloads where frontier precision is not required on every query.
Grok 4.3 went GA on 30 April with a 40% input price cut, now priced at $1.25 per million input tokens via the xAI API. It brings a 1-million token context window and stronger performance on real-time data tasks than GPT-5.5 or Claude, given its direct X/Twitter data integration. For social media monitoring, live news analysis, and trend tracking, Grok 4.3 is the most practical choice at this price point.
The dark horse: Kimi K2.6 from Moonshot AI
If one story flew under the radar this week, it is Kimi K2.6. Moonshot AI’s 1.6-trillion-parameter Mixture-of-Experts model scored 58.6% on SWE-bench Pro, within 6 points of Claude Opus 4.7 and matching GPT-5.5 on the same benchmark. It won a programming challenge that Claude, GPT-5.5, and Gemini all failed.
The pricing argument is hard to ignore. At $0.60 per million input tokens and $2.50 per million output, it costs roughly 8x less than Opus 4.7 for production coding workloads. Its multi-agent architecture, Agent Swarm, scales to 300 parallel sub-agents for long-horizon tasks. For teams that need near-Opus coding quality at volume pricing, it is worth testing before committing to a more expensive primary model.
What this means for you: final verdict
The AI market in June 2026 rewards routing over allegiance. No single model leads every benchmark, and the pricing gap between the cheapest and most capable options has never been wider.
For professional writing and reasoning, Claude Opus 4.7 and GPT-5.5 trade blows at the top. For complex software engineering, Claude’s lead is measurable. For budget-conscious production workloads, DeepSeek V4 Flash at $0.14 per million tokens is the clear starting point. For real-time data tasks, Grok 4.3 is the tool. Google’s new Gemini lands somewhere in the middle, a useful option for teams already embedded in the Google ecosystem.
The most productive strategy right now is a tiered approach: use a cheap model for routine queries, a mid-tier model for professional work, and a frontier model for the tasks that genuinely need it.
Frequently asked questions
What was the biggest AI news story this week in June 2026?
Google I/O 2026 dominated headlines on 19-20 May, with a new Gemini model expected alongside Googlebook and Android XR hardware. However, the story with the most lasting impact is Claude Opus 4.7’s coding lead and DeepSeek V4 Flash’s continued dominance on cost-per-token pricing.
Is Claude Opus 4.7 better than GPT-5.5 right now?
It depends on the task. Claude Opus 4.7 leads on complex software engineering, scoring 64.3% on SWE-bench Pro compared to GPT-5.5’s 58.6% on the same benchmark. GPT-5.5 leads on agentic terminal workflows and computer use tasks. For factual precision, Claude hallucinates significantly less in comparable testing.
Is DeepSeek V4 actually good enough to replace GPT or Claude?
For many routine production workloads, yes. DeepSeek V4 Flash at $0.14 per million input tokens handles high-volume queries at a 14x cost advantage over GPT-5.5. For the most demanding reasoning or coding tasks, Claude Opus 4.7 and GPT-5.5 still lead. Most teams benefit from using both at different query tiers.
What is Grok 4.3 and is it worth trying?
Grok 4.3 went GA on 30 April 2026 with a 40% input price cut, landing at $1.25 per million tokens via xAI’s API. Its key advantage is real-time data access through X/Twitter integration, making it the strongest option for live news analysis and social trend monitoring. Its 1-million token context window also makes it competitive for long-document tasks.
Which AI model should I use for coding in June 2026?
Claude Opus 4.7 leads on SWE-bench Pro, the benchmark most reflective of real-world engineering work. GPT-5.5 is close behind on agentic coding tasks. Kimi K2.6 offers near-Opus performance at roughly 8x lower cost and is worth testing for high-volume production coding. DeepSeek V4 Flash is the budget option for less complex code generation.
Author: The GrabbedDeals editorial team tests and reviews tech across every major category, from smartphones and laptops to AI tools and smart home devices. Our buying guides are built on the latest real-world data, independent expert reviews, and current pricing.
Explore our more pages – AI Tools & Productivity | Education & Learning | Travel | Smartphone Ecosystems | Laptop & PCs | Audio & Sound Systems | Gaming & Photography | EV & Green Tech | Digital Marketing & SEO | Smart Tech Deal & Buying Guides