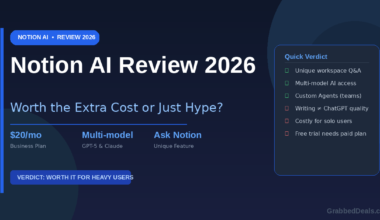
Gemini 3.5 Flash is the most disruptive AI model of mid-2026, and if you are still defaulting to GPT-4o or Claude Sonnet 4.6, you may be overpaying for tasks where Google’s newest model now leads. Launched at Google I/O on May 19, 2026, it delivers Pro-level reasoning at Flash-class speed. This comparison breaks down all three models on benchmarks, pricing, and real-world use cases so you can route your workloads correctly.
Key takeaways
- Gemini 3.5 Flash scores 55 on the Intelligence Index, ahead of Claude Sonnet 4.6 (52), and leads every model on MCP Atlas tool-use at 83.6%.
- Claude Sonnet 4.6 leads on SWE-Bench Verified software engineering at 79.6%, making it the top choice for production code work.
- GPT-4o carries an October 2023 knowledge cutoff and a 128K context window, both significant disadvantages in mid-2026.
- Gemini 3.5 Flash costs $1.50/$9 per million tokens versus Sonnet 4.6’s $3/$15, making it roughly 2x cheaper on input for comparable performance.
- There is no universal winner: the right model depends on your specific workload.
What is Gemini 3.5 Flash and why does it matter?
Google launched Gemini 3.5 Flash at Google I/O 2026 as the first model in its 3.5 generation. The headline is one that would have been implausible a year ago: a Flash-tier model that outperforms the previous generation’s Pro on agentic and coding benchmarks while running at approximately 284 tokens per second, roughly 4x faster than competing frontier models.
GPT-4o, by contrast, was released in August 2024 with an October 2023 knowledge cutoff and a 128K context window. It remains capable for basic tasks, but it competes against models that are significantly more capable and only modestly more expensive.
Head-to-head benchmark comparison
The figures below are drawn from official vendor model cards, Artificial Analysis, and BenchLM evaluations published within 48 hours of Gemini 3.5 Flash’s May 19 launch.
MCP Atlas (multi-step agentic tool-use): Gemini 3.5 Flash leads at 83.6%. Claude Sonnet 4.6 follows at 79.1%. GPT-4o does not carry a published MCP Atlas score and its older architecture places it well behind both newer models on structured tool-call workflows.
SWE-Bench Verified (real-world software engineering): Claude Sonnet 4.6 leads at 79.6%. Gemini 3.5 Flash posts a Terminal-Bench 2.1 result of 76.2%, above the prior generation Gemini 3.1 Pro score of 70.3%.
Speed: Gemini 3.5 Flash generates approximately 284 tokens per second. Claude Sonnet 4.6 runs at roughly 60 tokens per second. GPT-4o runs at approximately 77 tokens per second. For high-volume agentic loops, Flash’s speed advantage is structural, not marginal.
Intelligence Index (Artificial Analysis composite): Gemini 3.5 Flash scores 55, ahead of Claude Sonnet 4.6 at 52.

Pricing breakdown: where each model lands
Gemini 3.5 Flash costs $1.50 input and $9.00 output per million tokens. Despite being a 3x increase over its predecessor Gemini 3 Flash, it remains roughly 50% cheaper on input than Claude Sonnet 4.6.
Claude Sonnet 4.6 is priced at $3.00 input and $15.00 output per million tokens. For developers who need maximum coding accuracy, the premium is justifiable.
GPT-4o costs $2.50 input and $10.00 output per million tokens. Given its age and smaller context window, it now offers the weakest value proposition of the three.
For a practical example: a 10-step agentic workflow with approximately 3,000 tokens in and 1,000 tokens out per step costs roughly $0.135 per run with Flash versus $0.24 with Sonnet 4.6. At thousands of daily agent runs, this compounds fast.
Verify current rates directly on Google’s Gemini API pricing page, Anthropic’s pricing page, and OpenAI’s pricing page.
Real-world use cases: which model to choose
For AI agents and multi-step tool workflows: Gemini 3.5 Flash is the clear recommendation. Its 83.6% MCP Atlas score is the highest of any tested model, and Google demonstrated it running 93 parallel subagents processing over 15,000 requests in 12 hours for under $1,000 via Antigravity 2.0.
For software engineering and code review: Claude Sonnet 4.6 remains the strongest choice. Its 79.6% SWE-Bench Verified score and strong code reasoning make it the default in Claude Code. If your AI is reviewing pull requests going into a production repo, accuracy matters more than throughput.
For general use and everyday tasks: GPT-4o still handles simpler conversational queries, but its October 2023 knowledge cutoff and 128K context limit are real constraints in mid-2026. Most users would benefit from switching to a current-generation model.
For multimodal tasks: Gemini 3.5 Flash leads on MMMU-Pro at 84.2%, the highest recorded score per Artificial Analysis. For workflows involving images or mixed-media documents at scale, Flash is the most capable option at a reasonable price.
Watch: Gemini 3.5 Flash at Google I/O 2026
Final verdict
Gemini 3.5 Flash is the standout AI model release of mid-2026 for anyone running agents or high-volume workloads. It leads on speed, tool-use benchmarks, and multimodal tasks while costing roughly half what Sonnet 4.6 charges on input. Claude Sonnet 4.6 remains the best model for production software engineering where accuracy is non-negotiable. GPT-4o is the weakest option of the three today and should only be retained where existing integrations make switching impractical.
Frequently asked questions
Is Gemini 3.5 Flash better than GPT-4o in 2026?
For most workloads, yes. It has a newer knowledge base, a 1M token context window versus GPT-4o’s 128K, and leads on agentic benchmarks. GPT-4o’s October 2023 cutoff is a meaningful disadvantage for current-events tasks or long-document work.
Which AI model is best for coding in 2026?
Claude Sonnet 4.6 leads on SWE-Bench Verified at 79.6%, making it the top pick for production coding, code review, and multi-file engineering. Gemini 3.5 Flash is a solid alternative for code generation at scale where cost is the priority.
How much does Gemini 3.5 Flash cost compared to Claude Sonnet 4.6?
Gemini 3.5 Flash costs $1.50 input and $9.00 output per million tokens. Claude Sonnet 4.6 costs $3.00 input and $15.00 output. Flash is approximately 50% cheaper on input and 40% cheaper on output.
Is GPT-4o still worth using in mid-2026?
It handles basic tasks, but its October 2023 knowledge cutoff and 128K context window limit its competitiveness. OpenAI’s newer GPT-5 series is a more relevant alternative for most professional use cases.
Which AI model is the fastest in 2026?
Gemini 3.5 Flash at approximately 284 tokens per second, which is roughly 4-5x faster than Claude Sonnet 4.6 and 3-4x faster than GPT-4o. For real-time agent loops and latency-sensitive applications, this is a decisive advantage.
Explore our page – AI Tools & Productivity